When it comes to options and flexibility, Axon Framework gives you a huge selection of options for where to store your events. From traditional RDBMS options like PostgreSQL or MySQL to NoSQL databases such as MongoDB.
Another option is Axon Server, AxonIQ’s in-house specialized Event Store and message delivery system. But why choose this option over the others? In this blog, we’ll take a look at the reasons we were compelled to build our own specialized store and the benefits it brings to you and ultimately your customers.
For a comprehensive explanation please check out the webinar recording here.
Event Store Requirements
On the surface the requirements for an Event Store seem relatively simple:
- Append events to an event stream
- Read events back in write order
With such a simple set of requirements, any of the options Axon Framework supports should be able to do the job. But as we dig deeper we find some more specific requirements:
Validate aggregate sequence numbers - Writing events for an aggregate we need to ensure the sequence numbers increase in order and that there are no two events with the same sequence number for an aggregate. This coincides with consistency in the ACID acronym.
Append multiple events at once - An executed command could produce multiple events. We need to ensure these events are either written together or none are written to the store (Atomicity).
Only read committed events - Ensuring stored events are only available to read once the transaction is committed to the store (Isolation).
Committed events protected against loss - Any database worth its salt needs to be resilient to data loss (Durability).
Snapshots - A single aggregate could have a huge number of events. Upon aggregate hydration from the Event Store, this could cause command execution to become very slow. The solution is to snapshot your aggregate and only load and hydrate events since the snapshot.
Read events since a point in time and pushing new events - Performant tracking processors responding to new events need to have these events pushed to them as soon as possible.
Constant performance as a function of storage size - Sometimes we have thousands of events occurring each second over an extended period of time, potentially spanning many years of system operation. This means our Event Store could contain billions of events. If our Event Store becomes slower as it fills up with all these events it will lead to significant performance degradation for the whole system.
Optimize for recent events - We’re usually only interested in reacting to the most recent events, especially if we’re using snapshotting. Therefore our Event Store should be optimized to retrieve these events quicker.
That completes the list of requirements for an Event Store which should influence you in making a decision on which one to use. We will now use these criteria to evaluate the different options available to us.
The Contenders
In this section, we’ll consider four general purpose options as well as two specialized options and see how they stack up against this list.
Relational Database Management Systems (RDBMS)
With advanced transactionality features and a long, well-established history, RDBMS’ hits a lot of the required points. However, the deal breaker here is their performance on write throughput:
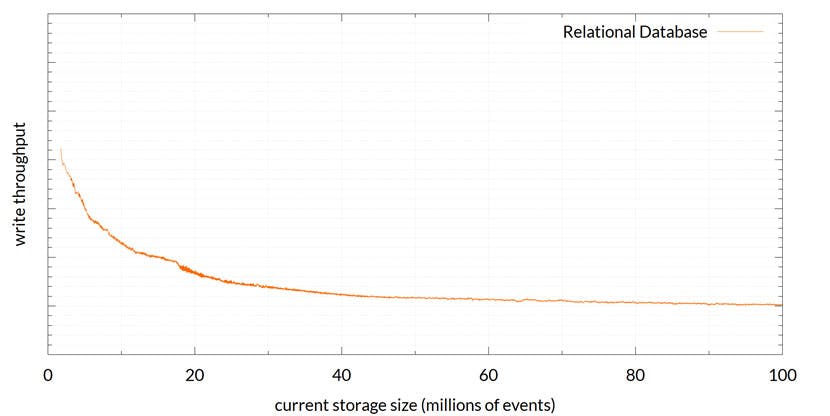
For this test, we measured write throughput of a popular RDBMS as it filled up with millions of events. Whilst throughput remains decent initially, performance halves after 20 million and then continues to fall gradually until stabilizing.
In addition, support for pushing new events to consumers is limited and is not a traditional strong point for the RDBMS option. On top of that, there is no optimization for accessing the frequently read, recent events.
The RDBMS option remains functionally complete but the points it falls down on are performance related and therefore there is a cost to be paid for using this option.
MongoDB
Scalability and strong ad hoc query support is the strength of this option. However, the element where document-based databases are not as strong is related to transactionality. MongoDB has recently announced support for multi-document transactions which somewhat mutes this point but this new feature currently comes with some limitations. We also have no easy method for pushing new events to clients so that we have optimal performance for processing events.
Finally, we run into trouble when generating sequence numbers for our events due to the eventual consistency in the cluster. MongoDB by design has no cluster-wide ACID transactions which would be required in order to achieve the sequencing guarantee. While there are workarounds for these problems you will only end up in a position similar to that of relational stores.
Kafka
Many people mention Kafka in the context of Event Sourcing since it shares the keyword ‘events’ as a key concept of the system. From its core design as a message delivery solution backed by a transaction log, it does not have an elegant method to store and retrieve event data when you consider the reading and writing requirements. Your choices between storing all events for an aggregate type in a single topic causes command-side scaling issues and the alternative to store aggregate per topic does not scale in Kafka due to the design of topics. Without going into more details here, check out the presentation by Allard Buijze, CTO of AxonIQ. And check out Vijjay Nair's blog mentioning how Axon compares to Apache Kafka.
Cassandra
Again another strong option for scalability with great features such as peer-to-peer connections and flexibility around the consistency needs for your reads and writes (eventual consistency versus highly consistent).
However, it is inefficient when it comes to guaranteeing sequencing numbering for our events. To guarantee sequence ordering in Cassandra you have to utilize its lightweight transaction feature which has considerable performance cost and, as described in the documentation, should be used sparingly. Since appending events is an extremely common operation for an event-sourced system, this rules Cassandra out of contention.
“EventStore”
The database “EventStore” (written with quotes to emphasize it is the name of the database) is a built for purpose solution and therefore, it meets all the requirements in our list. “EventStore” is a popular option which is written in .NET (with Java clients written using Akka) and is generally seen as part of the .NET ecosystem.
A key feature of “EventStore” is that projection (or event handling) logic is placed and executed within the Event Store itself using Javascript. While this is a tempting proposition, it diverges from our view that the Event Store should store events, and that projection logic should be handled by the consumers themselves. This allows you a greater degree of flexibility over how to handle your events and not being limited to the functionality of Javascript logic available on the store.
Axon Server
Axon Server is a zero-configuration message router and event store that combines gracefully with Axon Framework to provide a solution to both storing events and delivering messages between components (more about Axon Server can be found here).
Needless to say, it ticks all these boxes. Axon Server is built from scratch in Java to specifically meet all of these requirements. It manages files directly and does not depend on an underlying database system to store its events.
It has open interfaces based on HTTP+JSON and gRPC and is a drop-in replacement Event Store for users already leveraging the benefit of Axon Framework.
A key advantage is speed, especially when compared to RDBMS option:
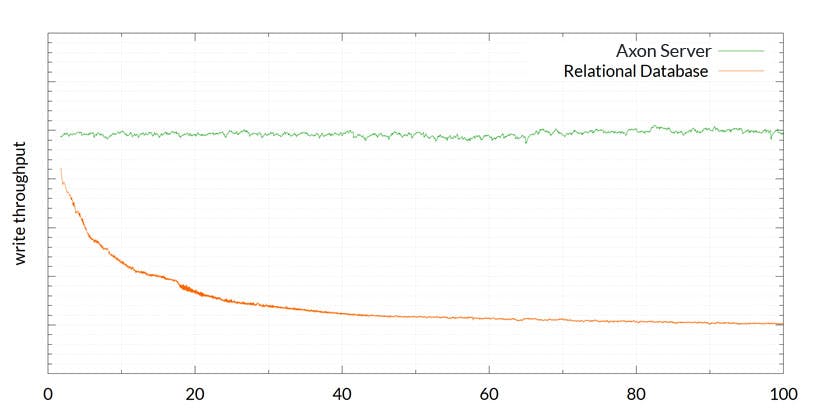
We run the test earlier again using the same hardware and as you can see, it not only outperforms the relation database but keeps a consistently efficient pace no matter how many events have been stored.
Conclusion
In this blog, we’ve summarized the requirements an Event Store database needs and looked at the various options available together with their advantages and disadvantages. To unleash the full set of features and performance of your Event Sourcing system, we recommend a specialized store and, particularly if you are already leveraging Axon Framework, choosing Axon Server is a logical choice to make.
Axon Framework is an open source Java framework for event-driven Microservices and Domain Driven Design. Axon Server is a zero-configuration message router and Event Store for Axon based application. You can download the quick start package here.


